How TELUS Digital built an expert-sourced multimodal dataset for STEM visual question answering

The human experience of the world is fundamentally multimodal in nature. Our understanding of our surroundings emerges from the simultaneous processing of visual scenes, auditory signals and more. Achieving comparable environmental understanding in artificial intelligence (AI) systems requires the ability to interpret and synthesize these varied modalities simultaneously.
Visual question answering (VQA) is a core research area advancing this goal, integrating computer vision and natural language processing to answer textual questions in the form of a prompt-response pair or question-answer (Q&A) pair with explanation, related to an image or other visual information.
VQA is a key post-training approach for the multimodal large language models (LLMs) and visual language models (VLMs) that power diverse applications, from assistive technologies to medical diagnostics and interactive education. However, as VQA is applied to difficult tasks in science, technology, engineering and math (STEM), models often lack deep, domain-specific understanding and the ability to perform multi-step logical analysis.
The challenge: Why existing VQA datasets fall short
Current multimodal benchmarks predominantly evaluate generic image comprehension or text-driven reasoning, lacking authentic scientific contexts that require domain-specific knowledge integration with visual evidence analysis. We identified several such key challenges in existing datasets:
Limited rationale in training data
Current training approaches for VQAs often rely on datasets dominated by short answers with limited rationales. For example, when answering a math question with a bar chart, a human would typically enumerate the bars and then calculate the total. However, writing out this enumeration process is far more cumbersome than simply providing the short answer. Consequently, annotated training data for VQA is predominantly composed of short answers, with minimal rationale provided. But developing true chain-of-thought (CoT) reasoning capabilities in multimodal models using VQA requires explicit training on data that includes these detailed reasoning steps.
Single-domain focus
In the real world, solutions often require a combination of knowledge from multiple STEM fields. Existing vision-language datasets, however, often concentrate on training and evaluating only one of the STEM subjects. For example, datasets like IconQA and Geometry3K focus on mathematics, while ScienceQA examines science-related skills. Hence an LLM or VLM's capabilities for integrating domain-specific knowledge with visual evidence analysis remains inadequately trained or assessed.
Insufficient diversity in visual content
The images used in training often consist of everyday photographs or simple diagrams, rather than the complex visualizations found in scientific literature. This gap between training data and real-world application scenarios severely limits model utility in professional and educational contexts.
The modality balance challenge
In VQA model development and training, achieving balanced learning that avoids bias toward either visual or question information is crucial. The primary challenge in VQA lies in eliminating noise while utilizing valuable and accurate information from different modalities. Models often develop shortcuts, over-relying on linguistic patterns in questions to predict answers without genuinely analyzing the accompanying images. Alternatively, they may focus excessively on salient visual features while ignoring crucial contextual information from the question.
Our solution: The advanced STEM VQA dataset
To address these gaps, we developed an expert- and tool-driven methodology for VQA dataset creation. This process is built on two core components:
- A global network of verified subject matter experts (SMEs).
- Our proprietary data annotation platform, Fine-Tune Studio (FTS).
Our objective was to create a benchmarkable multimodal dataset specifically designed for fine-tuning and evaluating scientific reasoning through domain-grounded visual question answering. This comprehensive, multimodal AI training resource features over 11,000 expertly crafted visual question-answer pairs spanning diverse STEM disciplines, each demanding domain knowledge, integration of visual evidence and higher-order reasoning.
Progressing complexity levels: The design of skills in STEM is important. We focus on both fundamental skills and expert-level skills based on high school, undergraduate and graduate curriculum. This broad complexity range ensures models are challenged and can generalize across all levels of expertise:
- Highschool: Testing basic reasoning and general knowledge.
- Undergraduate: Requiring deeper subject understanding and analytical thinking.
- Graduate: Demanding specialized knowledge, critical thinking and complex problem analysis.
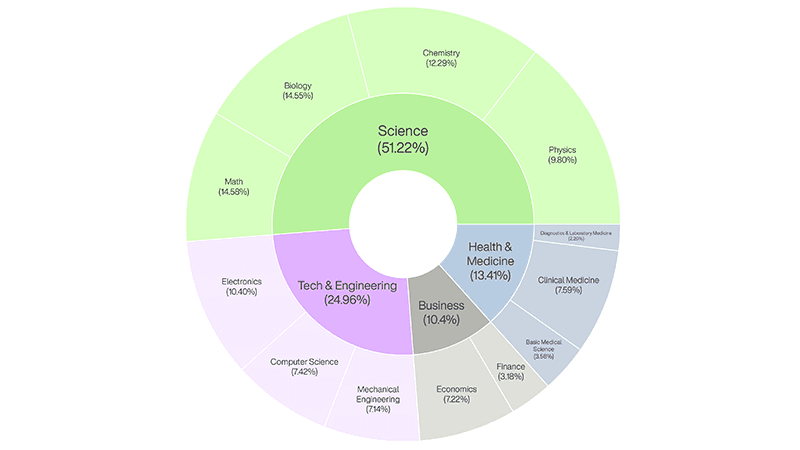
Balanced domain distribution: We move beyond single-subject testing. Our dataset spans domains and subdomains including:
- Science: Math, biology, chemistry, physics.
- Business: Economics, finance.
- Tech and engineering: Electronics, computer science, mechanical engineering.
- Health and medicine: Basic medical science, clinical medicine, diagnostics and laboratory medicine.
Dataset design and development process
Phase 1: Expert-driven content creation
Built based on the massive multi-discipline multimodal understanding and reasoning (MMMU) benchmark framework, the entire dataset is 100% human-generated by qualified professionals. We recruited a diverse team of SMEs through our contributor management platform Experts Engine, including university professors, researchers and industry practitioners with advanced degrees (Master’s and Ph.D.) in physics, chemistry, finance, medicine and engineering.
- Challenging image selection: Experts source high-quality, complex visuals from open-source textbooks and scientific literature. These include technical illustrations, data visualizations, medical scans and schematics that require domain-specific knowledge to interpret.
- Cognitive redaction: To prevent models from finding simple shortcuts, our SMEs strategically obscure or remove textual labels and direct answers from the images if needed. This compels the model to interpret the visual data itself and apply domain knowledge.
- Original Q&A generation: Based on the image, the SME constructs an entirely original question, a concise answer and, most importantly, a detailed explanation. All Q&A pairs are novel and not available in any open-source repository.
- The F.A.B. framework: To ensure high-quality CoT rationales, we require SMEs to structure their explanations using our F.A.B. (Facts, Argument, Bingo) framework. This pedagogically sound structure requires them to:
- Facts: Explicitly state the visual facts observed in the image.
- Argument: Articulate the logical argument that connects those facts to domain-specific knowledge.
- Bingo: State the final, correct answer.
This framework provides a transparent, verifiable logic trail for each answer, which is essential for training models on trustworthiness and explainability.
Phase 2: The Fine-Tune Studio platform & QA workflow
All curation and validation are managed on our proprietary platform, Fine-Tune Studio (FTS), which is designed to enforce quality and originality at scale. FTS provides built-in automated checks, including grammar, spelling, AI detection and plagiarism checkers, to ensure all submitted content is original and well-formed. In addition to these automated checks, we established a detailed quality control rubric to systematically evaluate each submission. This rubric includes parameters to check for factuality, coherence, naturality of responses, explainability, accuracy, specialized domain knowledge and image utilization.
FTS also facilitates a multi-tier human validation workflow to ensure every single data point is accurate, logical and pedagogically effective. Each task passes through independent expert review for factual accuracy and logical soundness, educational review by instructional design specialists for pedagogical effectiveness, quality control audits for grammar and formatting and final validation against established curricula and industry benchmarks before inclusion in the dataset.
The following is a sample VQA created on our FTS platform:

The advantages of our VQA dataset
- Complex reasoning and planning: Trains the model to break down complex problems into manageable, sequential steps, mimicking human cognitive processes.
- Trustworthiness and explainability: Provides a transparent, verifiable logic trail for each answer, allowing human experts to audit the model's reasoning.
- Reduced hallucinations: Grounds the model's output in a logical sequence derived from visual evidence, preventing unconstrained, factually incorrect generation.
- Enhanced zero-shot generalization: Exposes the model to diverse concepts and reasoning patterns, improving its ability to handle novel problems.
- Domain specialization: Provides the specific, high-quality data needed to fine-tune generalist VLMs into expert systems for high-value verticals. Training on complex, technical images (diagrams, charts, medical scans) makes the model more resilient to noisy or out-of-distribution real-world data compared to training only on generic web photos.
Maintaining relevance against state-of-the-art models
A dataset's utility as a training or evaluation tool diminishes if it becomes too easy for state-of-the-art (SOTA) models. A key part of our process is to continuously benchmark the dataset against the latest SOTA reasoning models.
This ongoing analysis helps us identify which types of problems remain difficult and guides the creation of new, more challenging content. Currently, the overall score of SOTA models against our dataset is approximately 52.49%, demonstrating that it remains a difficult benchmark and that our expert-led creation process successfully produced tasks that can help further improve current AI reasoning capabilities.
Take advantage of our off-the-shelf VQA dataset
Developers can leverage our diverse dataset to build and validate models for sophisticated real-world tasks. We offer flexible options for acquiring the VQA dataset: the full 11,000+ VQA dataset or the curated complex subset. Contact our team of experts to learn how our off-the-shelf, licensable dataset can help you achieve your STEM-focused AI goals faster and at a lower cost.




